
How I built a specialized AI model for generating realistic cursed horror imagery using FLUX.1-dev and a custom dataset of creepy content
The Problem: AI Art Lacks Realistic Creepy Horror
Years ago I played around with training a horror dataset for StyleGAN2 on a 2080TI for several weeks and I got a decent results.


Bottom – Results after 280 iterations
So when I revisited recent diffusion models such as Stable Diffusion and FLUX.1-dev, I noticed there were plenty of LoRAs for anime, portraits, and landscapes, but the horror and creepy content being generated felt… well, fake.
The AI was producing cartoonish monsters and generic spooky scenes that lacked the raw, unsettling atmosphere of real horror content. I wanted something that could generate imagery that felt like it came from a found footage film, a creepypasta story, or an abandoned building exploration video.
So I decided to train my own LoRA specifically for horror and creepy content as I wanted to create something that could generate genuinely unsettling, realistic horror imagery.
The Hardware: RTX 4090 and RTX 5090 on RunPod
Training LoRAs require computational power, and I wasn’t about to buy a RTX 5090 just for this. Fortunately GPU-cloud instances exist, like RunPod! (not sponsored). And for testing I can leverage my RTX 4090 at home.
Specifications:
- Training: RTX 5090 with 32GB VRAM
- Memory Requirements: FLUX.1-dev model needs at least 20GB VRAM for efficient training
- Storage: 100GB+ for model weights, datasets, and training artifacts
The RTX 5090 with 32GB VRAM, allowed me to run the FLUX.1-dev model with gradient check-pointing enabled, allowing for stable training without memory issues.
The Foundation: FLUX.1-dev Model
I chose FLUX.1-dev as my base model for several reasons:
- Superior Image Understanding: FLUX models excel at understanding complex visual content and generating coherent imagery
- Resolution Flexibility: Supports multiple resolutions (512×768, 1024×1280) for diverse training data
- Modern Architecture: Built on the latest diffusion model research, offering better quality than older Stable Diffusion models
Dataset Creation
The most critical part of training any LoRA is the dataset. I needed images that captured the essence of real horror, not just stock photos of haunted houses, but genuine creepy content that felt authentic.
Step 1: Image Collection
I gathered a dataset of 100 images, carefully curated horror images, focusing on:
- Found footage aesthetics: Grainy, low-quality imagery that feels real
- Abandoned locations: Buildings, hospitals, schools with genuine decay
- Creepy atmospheres: Dark rooms, shadowy figures, unsettling lighting
- Realistic horror: Content that looks like it could exist in the real world






Step 2: Enhanced Captioning with Florence-2
Instead of manually writing captions, I put together an automated captioning system using Microsoft’s Florence-2 model, to capture the feeling of horror.
The Captioning Process:
# Florence-2 generates base descriptions
base_caption = "dark abandoned hallway with flickering lights"
# Enhanced with horror-specific tags
enhanced_caption = f"{base_caption}, horror content, creepy atmosphere, grainy footage, dark and unsettling, horror movie style, unsettling atmosphere, horror aesthetic, low light, shadowy figures, eerie lighting, disturbing imagery, horror movie quality"Key Horror Descriptors Added:
horror content– Core classificationcreepy atmosphere– Emotional tonegrainy footage– Found footage aestheticdark and unsettling– Visual moodshadowy figures– Character elementseerie lighting– Atmospheric details
Step 3: Text Filtering
I implemented text filtering to remove images with text overlays, ensuring the LoRA learned from pure visual horror rather than text-heavy content that could interfere with training.
The Training Configuration
The training configuration is mostly the same as the default AI-Toolkit parameters.
Key Training Parameters:
name: "horror-creepy-content-generation"
network:
type: "lora"
linear: 32
linear_alpha: 32
train:
batch_size: 1
steps: 3000
gradient_accumulation_steps: 1
train_unet: true
train_text_encoder: false
gradient_checkpointing: true
noise_scheduler: "flowmatch"
optimizer: "adamw8bit"
lr: 1e-4
dtype: bf16
model:
name_or_path: "black-forest-labs/FLUX.1-dev"
is_flux: true
quantize: trueWhy These Settings Work:
- LoRA Rank 32: Provides enough capacity to learn horror patterns without over-fitting
- Flow Matching: Better training stability than traditional DDPM schedulers
- Gradient Check pointing: Essential for memory efficiency on 24GB VRAM
- BF16 Precision: Optimal balance of speed and stability for FLUX models
Building the Workflow
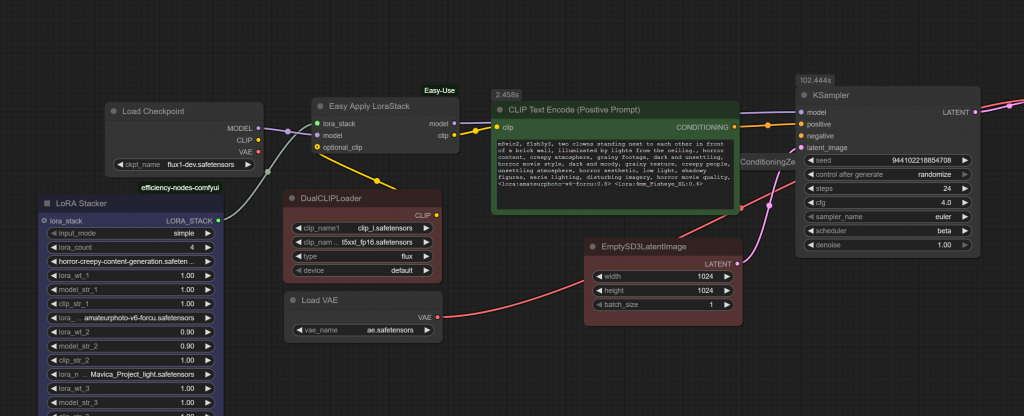
Picking ComfyUI as the choice to load FLUX.1-dev and LoRAs due to its extensive library of 3rd party plugins, and visual workflow design.
ComfyUI Settings I Used:
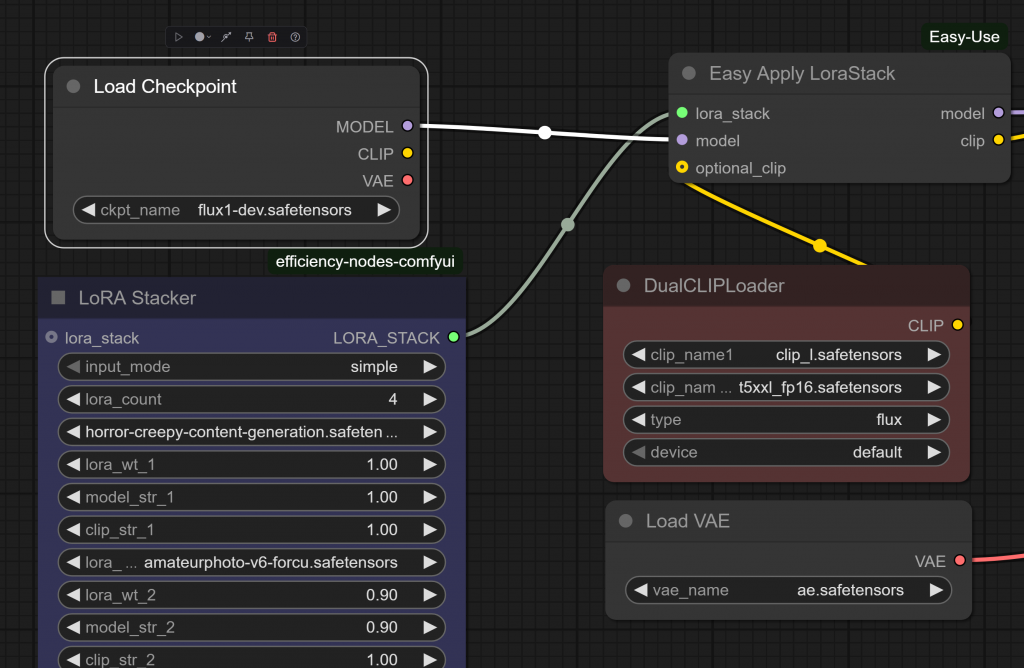
- LoRA Stacker: Provides the capability to load multiple LoRAs to fine tune the final image output
- Dual CLIP Loader: clip_l and t5xxl are common for FLUX as our LoRAs don’t come embedded with CLIP
- VAE: Just like CLIP, we need to load a vae, I used ae.safetensors
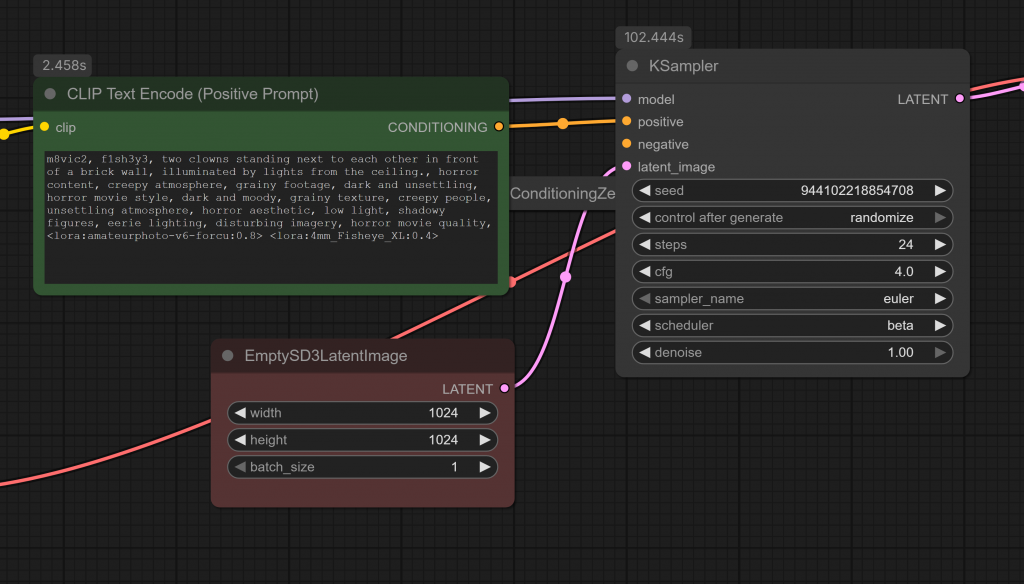
- K Sampler Parameters:
- Steps: 24 (recommended 30 as maximum)
- CFG: 4 or 1 since FLUX.1-dev doesn’t use negative conditioning
- Sampler Name: Euler
- Scheduler: Beta
- De noise: 1.00
The Results: Realistic Horror Generation
What the LoRA Learned:
After 3000 training steps, the LoRA began producing genuinely unsettling imagery. The key ingredient was that it wasn’t just generating generic “spooky” content, it was creating images that felt like they came from real horror media!
- Atmospheric Horror: Dark, moody scenes with proper lighting
- Found Footage Aesthetics: Grainy, low-quality imagery that feels authentic
- Realistic Settings: Abandoned buildings, dark hallways, creepy rooms
- Emotional Impact: Images that genuinely unsettle rather than just look “scary”
Sample Generated Prompts:
- “dark abandoned hallway with flickering lights, horror content, creepy atmosphere, grainy footage, dark and unsettling, horror movie style”
- “shadowy figure lurking in doorway, horror content, creepy atmosphere, grainy footage, dark and unsettling, horror movie style”
- “low light scene with eerie shadows and broken windows, horror content, creepy atmosphere, grainy footage, dark and unsettling, horror movie style”







Technical Deep Dive: The Captioning System
The automated captioning system I put together helped immensely tag/label the dataset. Here’s how it worked:
Florence-2 Integration
class EnhancedCaptioner:
def __init__(self, filter_text_images=True):
# Store text filtering preference
self.filter_text_images = filter_text_images
# Initialize microsoft for captioning
try:
model_name = "microsoft/Florence-2-base"
# Set device for pipeline
device_id = 0 if torch.cuda.is_available() else -1
from transformers import AutoProcessor, AutoModelForCausalLM
# Determine the dtype to use consistently
model_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
self.processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
self.caption_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=model_dtype,
trust_remote_code=True,
device_map=None # Don't use device_map initially
)
# Manually move model to device if CUDA is available
if torch.cuda.is_available():
self.caption_model = self.caption_model.to(self.device)Horror-Specific Enhancement
def _enhance_caption_for_thumbnails(self, base_caption, extracted_text, video_metadata):
enhanced_parts = [
"horror content",
"creepy atmosphere",
"grainy footage",
"dark and unsettling",
"horror movie style"
]
# Add visual style descriptors
enhanced_parts.extend([
"dark and moody",
"grainy texture",
"creepy people",
"unsettling atmosphere",
"horror aesthetic"
])
return ", ".join(enhanced_parts)Text Detection and Filtering
def detect_text_in_image(self, image_path):
# Use Florence-2 to detect if image contains text overlays
prompt = "<TEXT_DETECTION>"
# Skip images with textTechnical Deep Dive: ComfyUI Workflow
If you want significantly faster generation use the flux.dev scaled fp8 with minor tweaks.
3rd party LoRAs can enhance your results
- Amateurphoto-v6-forcu.safetensors
- Mavica_Project_light.safetensors
- Trigger word – m8vic2
- 4mm_Fisheye_XL.safetensors
- Trigger word – f1sh3y3, 4mm fisheye, ultra-wide angle, GoPro
Lessons Learned and Best Practices
- Dataset Quality Over Quantity
- 100 carefully curated images with perfect captions proved more effective than thousands of mediocre examples. Each image needed to contribute meaningfully to the horror aesthetic.
- Caption Consistency is Key
- Using the same horror descriptors across all images ensured the LoRA learned consistent patterns. The model needed to understand what “creepy atmosphere” meant across different visual contexts.
- Hardware Requirements Matter
- Training FLUX models requires serious GPU power. The RTX 5090’s 32GB VRAM was the minimum viable configuration for stable training.
- Iterative Refinement
- The training process involved multiple iterations of dataset refinement, and caption adjustment. Each iteration improved the model’s understanding of horror aesthetics.
Future Applications and Expansions
This horror LoRA opens up several possibilities:
- Creepy pasta Story Generation
- Combine the LoRA with text generation models to create illustrated horror stories with matching imagery.
- Found Footage Film Production
- Create realistic horror film stills and promotional materials that feel authentic to the genre.
- Interactive Horror Experiences
- Build AI-powered horror experiences where users can generate custom creepy imagery based on their descriptions like the work done here by SkyworkAI/Matrix Game 2.
Conclusion: The Future of AI-Generated Horror
Training this custom horror LoRA taught me that AI art generation is only as good as the data and methodology behind it. By focusing on quality over quantity, implementing intelligent captioning, and leveraging the right hardware, it’s possible to create AI models that generate genuinely unsettling, realistic horror content.
The key insight is that AI doesn’t just need to learn what horror looks like, it needs to understand what horror feels like. Through careful dataset curation, consistent captioning, and iterative training, we can teach AI to generate content that captures the emotional essence of horror rather than just its visual tropes.